大数据学习
–MapReduce程序编写
环境:
idea: ultimate 2018.1
运行流程示意图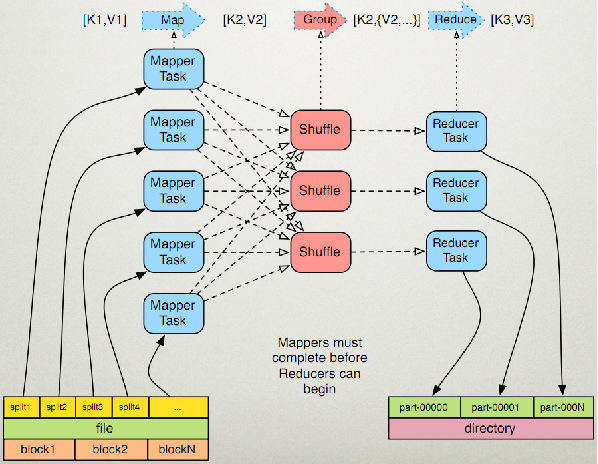
以wordCount为例
Mapper:
数据输入进来的第一步,可以定制键值对
Mapper类需要继承Mapper父类
public static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
protected void map(LongWritable key,Text value, Context context) throws IOException, InterrupteException{
String[] words = value.toString().split(",");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
Mapper父类一共有4个参数
1:是数据的偏移量,例如刚进来为0,第二次进来因为已经读完了一行数据,他就等于第一行数据的长度+0,以此类推
2:表示下一行数据,在这个例子里面是一行的字符,也就是下面map方法中的value
3:输出的key的数据类型
4:这个表示map方法产生的value类型,在我们这个例子中是IntWritable型的,所以我们继承的时候要写IntWritable
map方法一共有3个参数
LongWritable key:偏移量
Text value:输入的这行的数据
Context:存储map运算后的数据,本例子中context.write(new Text(word),new IntWritable(1)),key是字母,value则为1,因为 字母出现一次就记一次
Reducer:
由流程图可以看出这是最后一步,就是总结的作用吧,汇总所有数据,然后进行输出
Reducer类需要继承Reducer父类
public static class HadoopReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//相同的key聚合 几种类型的key调用reduce几次
private IntWritable count = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
count.set(sum);
context.write(key, count);
}
}
Reducer父类一共有4个参数
1:输入的key数据类型,本例中是字母,我们用Text存储
2:输入的value数据类型,本例中是频率,我们用IntWritable来存储
3:输出key的数据类型
4:这个表示reduce方法产生的value类型,在我们这个例子中是IntWritable型的,所以我们继承的时候要写IntWritable
reduce方法一共有3个参数
Text key:map运算设置的key
Iterable
Context:存储reduce运算后的数据,本例子中context.write(new Text(word),new IntWritable(1)),key是字母,value则为频 率
main方法测试
Configuration config = new Configuration(); //初始化配置
Job job = Job.getInstance(config);//把任务封装到job对象
job.setJarByClass(HadoopDriver.class);//设置任务启动类
job.setMapperClass(HadoopMapper.class);//设置mapper类
job.setReducerClass(HadoopReducer.class);//设置reducer类
//设置输出的key和value的数据类型, 如果map的输出和reduce输出key-value类型一致 可以不写map
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//告诉hadoop集群以什么方式读取数据,从哪里读取
job.setInputFormatClass(TextInputFormat.class);//设置输入格式,默认是key-value输入
TextInputFormat.setInputPaths(job, new Path("D:\\word.txt"));//设置输入目录,本例也就是需要统计字频的文件
//告诉hadoop集群以什么样的方式写入数据,数据写入到哪里
job.setOutputFormatClass(TextOutputFormat.class);//设置输出格式,默认是key-value输出
Path path = new Path("D:\\wordcount");//新建路径
FileSystem fs = FileSystem.get(config);//新建文件系统
if (fs.exists(path)) {//判断路径是否存在,如果存在则删除,hadoop的严格的容错性保证每次输出一定是新目录
fs.delete(path, true);
}
TextOutputFormat.setOutputPath(job, path);//设置输出路径
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);//当任务完成时,系统退出

