大数据学习
–Hadoop安装与配置
环境:
jdk:1.8
hadoop:2.6.1
linux:centOS 6.7
VM:15.0.0
外部环境:windows 10家庭版
远程工具:SecureCRT
1. 网络环境配置
因为我是处于学习阶段,所以使用vm虚拟机模拟大数据环境。设置3个服务器,选定一个作为主机。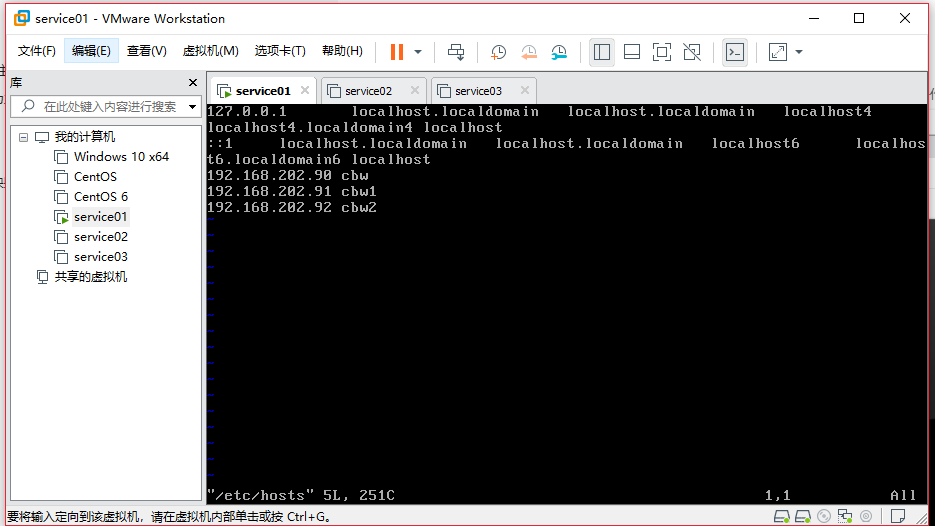
我选择第一个,也就是service01为主机。
首先配置ip,将三个服务器ip设置到同一网段。
修改ip地址有两个方法,一个是修改文件,还有个是进入setup修改。
通过文件修改:
vim /etc/sysconfig/network-scripts/ifcfg-eth8
输入以上命令进入eth8这块网卡,这个虚拟网卡是vm虚拟机自带的,还有一块eth0,我们使用哪一个都一样,只是一个名字。进入后我们可以看到以下界面: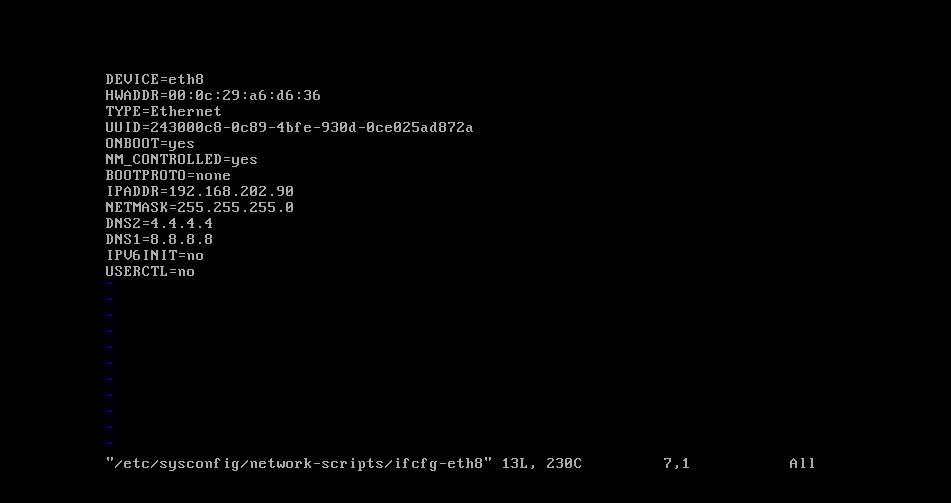
DEVICE=网卡名称
HWADDR=物理地址(硬件地址)
TYPE=网卡类型(可以设置成static,静态永久的)
UUID=是虚拟机自己设置的
ONBOOT=是否开机启动
IPADDR=ip地址,也就是我们要修改的
NETMASK=子网掩码
我们需要修改ip地址,将它的地址和我们自己的电脑,虚拟机的ip这3者的ip设置到同一网段内,另外两台同理,一样设置。
通过setup界面修改:
直接输入setup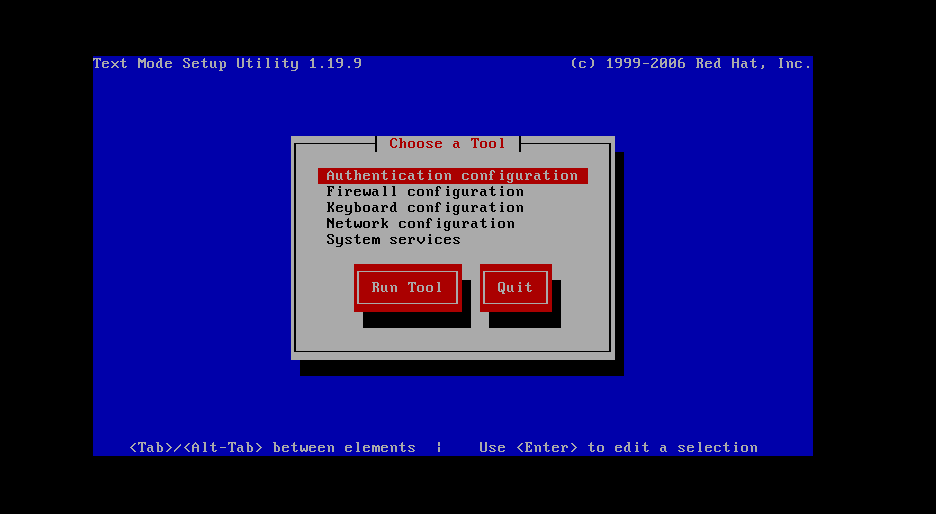
进入以上界面,选择第四个,network configuration
选择第一个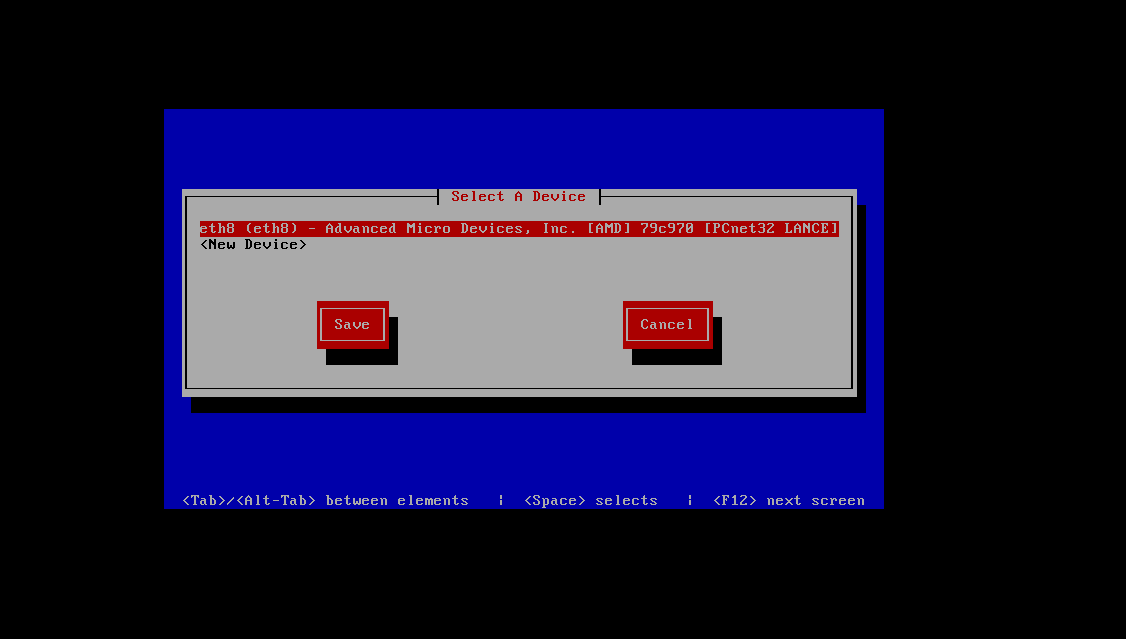
可以看到我们的eth8这块网卡,选择它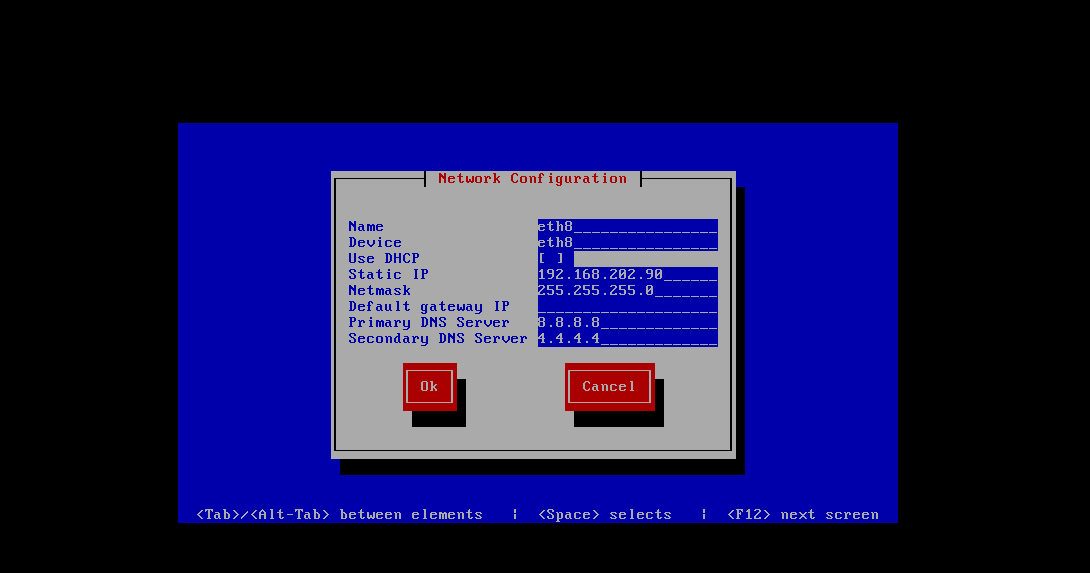
这里我们可以直接修改网卡名和ip地址,修改完成后,save&quit,然后执行service network restart
重启网络服务,再次输入ifconfig
查看,可以看到,ip已经修改了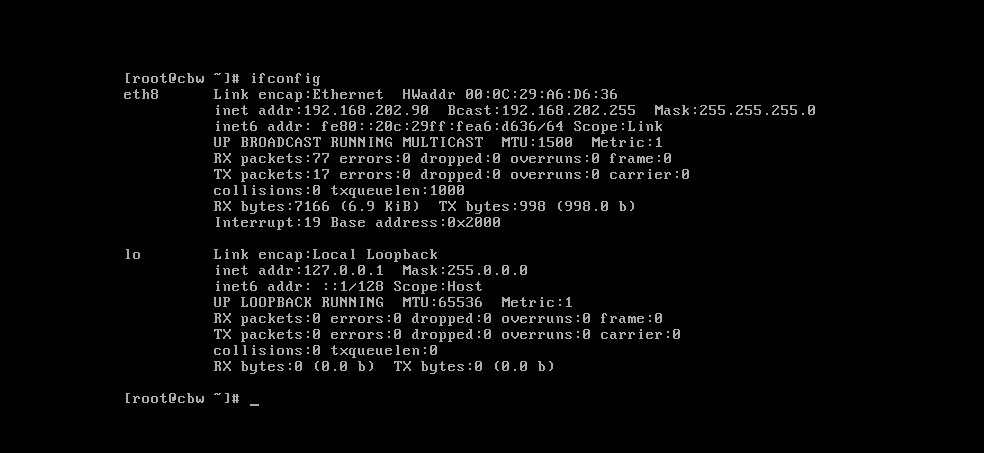
下一步修改主机名,不然三个服务器的主机名默认都是root,这对后来设置域名映射时会很麻烦。
我们输入下面的命令,进入network文件。vim /etc/sysconfig/network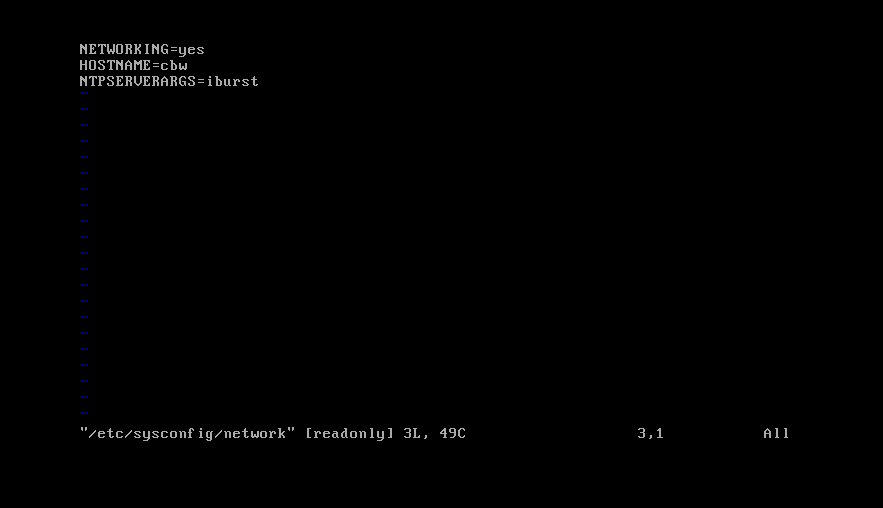
里面的HOSTNAME就是你的主机名,默认是root,修改成自己的,然后ESC,shift+:,wq保存退出
可以看到,主机名改变了
2. 域名映射,ssh免登陆设置
为了以后使用ssh登录其他服务器方便,我们要做域名映射,不然,每次都是输入一串ip地址,太麻烦,我们要在hosts文件里面修改域名映射,按照上面的教程,我们应该已经将3台服务器的主机名都设置好了,我的是cbw,cbw1,cbw2.
输入vim /etc/hosts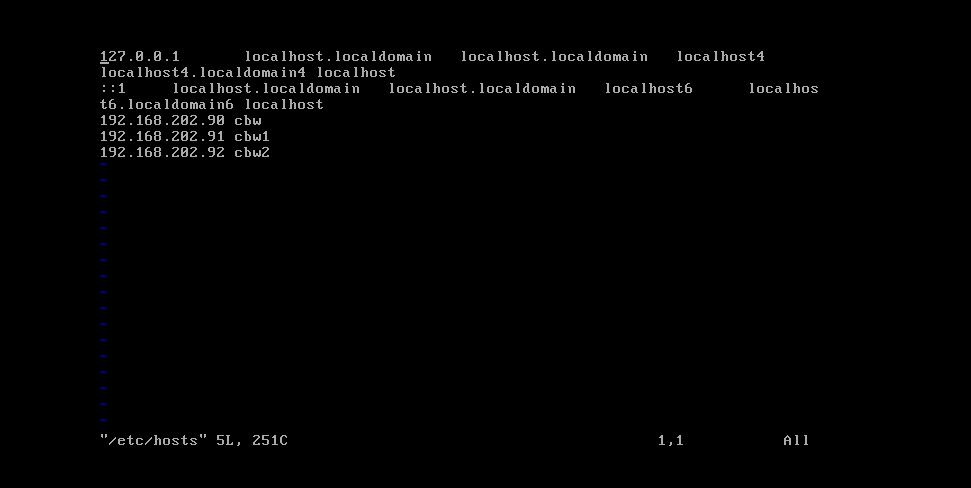
进入hosts文件,直接换行,写ip地址,空格,主机名,3台服务器都设置,然后保存退出
使用ping测试一下是否能通。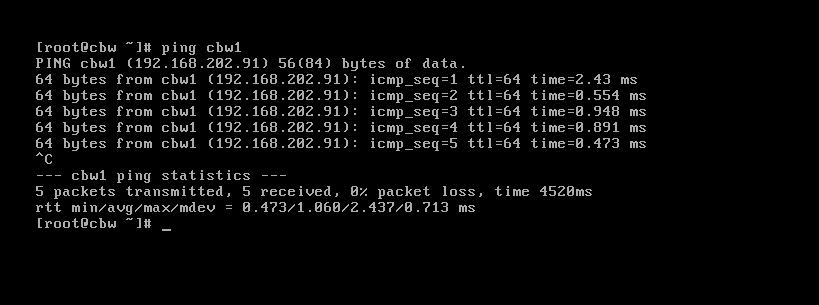
可以看到,我们直接ping名字也能ping通,说明设置成功。其他几台服务器一样设置,为了方便,我们采用分发的方式,直接将这个文件分发给另外两台服务器。scp /etc/hosts cbw1:/etc/hosts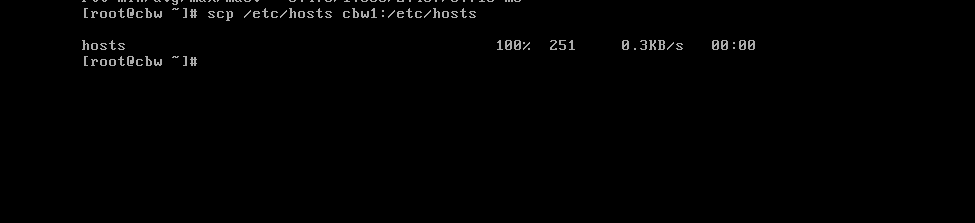
分发成功,cbw2同理,我们去看看另一台服务器是否能ping域名ping通。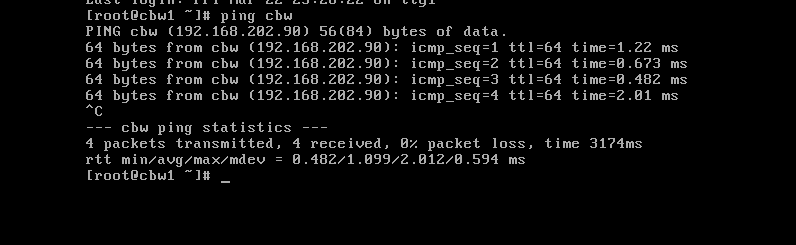
可以看到,我通过cbw1直接ping主机cbw,是可以ping通的,说明文件分发成功,cbw2也通过相同的方式分发就行。
ssh免登陆设置:
我们使用ssh远程登录其他服务器的时候要输入密码,而因为hadoop的原因,有很多时候要多次登录其他服务器,每次都输入密码的话,很浪费时间和操作,而且我们使用hadoop的时候基本没有什么安全隐患,所有没必要设置每次都登录输入密码,这样会让操作变繁琐,因此我们要设置ssh免登陆。
先在root目录下查看是否有.ssh文件夹,如果没有的话就新建一个。
然后输入以下命令ssh-keygen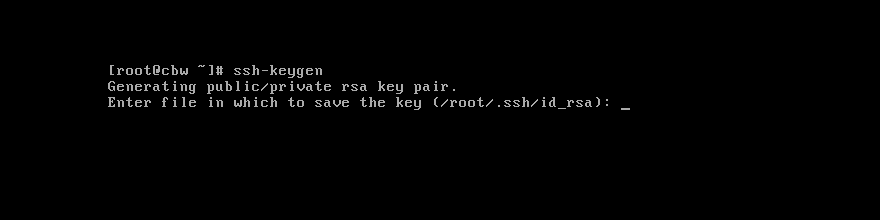
然后一直回车,直到出现一个图案
这个时候代表获取密钥成功了,下一步,分发密钥给其他服务器ssh-copy-id cbw1
然后它会提示你输入密码,输入密码之后就代表成功了,下次使用ssh命令进入cbw1时是不用输入密码的,同理,cbw2也配置一下,ssh免登陆设置成功。
3. 服务器配置jdk环境
以下所说的jdk都是你自己下载的jdk压缩包名,或者解压后的jdk文件夹的名字,我自己的改名叫jdk,方便修改其他东西
首先下载好jdk
下载地址
要安装一种远程连接工具,xshell或secureCRT都行,我使用的是secureCRT,连接好主机后,使用alt+p调出sftp窗口
put <文件路径>
回车,上传jdk到服务器,然后查看root目录下,文件是否上传成功
可以看到,jdk上传成功
再将jdk移动到/usr/文件夹下面mv jdk /usr/
然后解压jdktar -xvzf jdk
解压成功,可以看到有很多jar包。
接下来就是配置环境变量了,进入/etc/profile/文件vim /etc/profile
跳到文件末尾,输入以下内容
export JAVA_HOME=/usr/jdk
export JRE_HOME=/usr/jdk/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

然后出去输入source /etc/profile
刷新文件并保存,再输入java -version
如果出现以上信息,说明jdk环境已经搭建完毕
然后,我们使用scp命令,将jdk和环境配置文件分发到其他的两台服务器上面scp -r /usr/jdk/ cbw1:/usr/jdk/scp /etc/profile/ cbw1:/etc/profile/
cbw2同理,然后去到另外两台服务器source一下文件,重新加载并生效source /etc/profile
此时,3台服务器的jdk都已经配置完毕
4. 服务器配置Hadoop环境
hadoop下载地址
找到相应版本下载即可
安装hadoop与jdk同理,上传hadoop压缩包,然后解压,然后放到/usr/里面,开始配置环境变量,进入/etc/profile/文件vim /etc/profile
跳到文件末尾,输入以下内容
export HADOOP_HOME=/usr/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

然后出去输入source /etc/profile
刷新文件并保存,再输入hadoop version
如果出现以上画面,说明环境配置完毕
5. Hadoop文件配置
cd /usr/hadoop2.6.1/etc/hadoop/
进入这个文件夹,我们需要配置6个文件:
hadoop-env.xml
这个文件用来配置jdk的根路径
export JAVA_HOME=/usr/jdk
在文件末尾加入jdk的路径,保存退出
core-site.xml
输入vim core-site.xml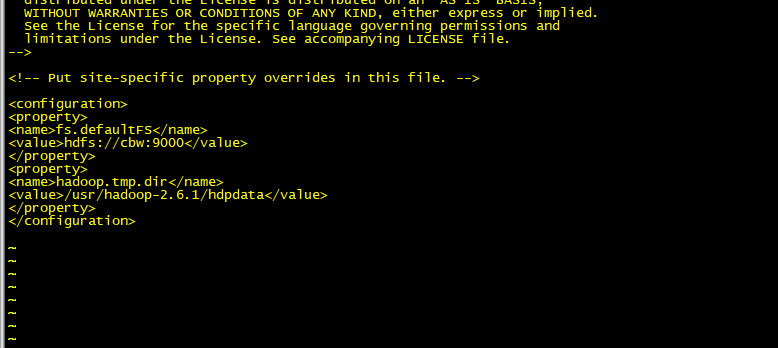
文件内容如上,我们使用默认的文件系统fs.defaultFS,我们需要修改的是fs.defaultFS的value,这个值是告诉文件系统他的老大在哪台服务器启动,也就是主机,我的自然是cbw,后面的9000是端口。下面的hadoop.tmp.dir是告诉系统,hadoop的源文件存放在哪个目录下,value就是我设置的目录,默认是在hadoop根目录下的hdpdata文件夹,如果没有这个文件夹,hdfs在格式化的时候会去自动创建这个文件夹。
hdfs-site.xml
这个文件是配置上传文件的blocksize副本数的
value设置为多少,block的副本数就是多少,如果不设置,它默认是3个,这里我们设置为2个
mapred-site.xml
这个是配置mapreduce所使用的框架
我们使用yarn框架
yarn-site.xml
这个文件配置yarn的主机和nodemanager的服务
yarn的主机我们当然选择cbw,然后nodemanager的value我们写mapreduce_shuffle
slaves
这个文件时配置所有服务器的
我们加上所有的服务器域名
到这里,需要配置的文件已经全部完成
然后格式化hdfshdfs namenode -format
格式化完毕,同理,我们要将hadoop文件夹分发给其他服务器,还有环境文件也要分发scp -r /usr/hadoop2.6.1 cbw1:/usr/hadoop2.6.1scp /etc/profile cbw1:/etc/profile
cbw2同理
然后别忘记保存生效source /etc/profile
到这一步hadoop的配置就完成了

