大数据学习
–idea上运行WordCount程序
环境:
idea:ultimate 2018.1
首先打开idea
界面是这样的,我们新建项目,选择maven项目,project SDK选择自己的jdk根目录,直接next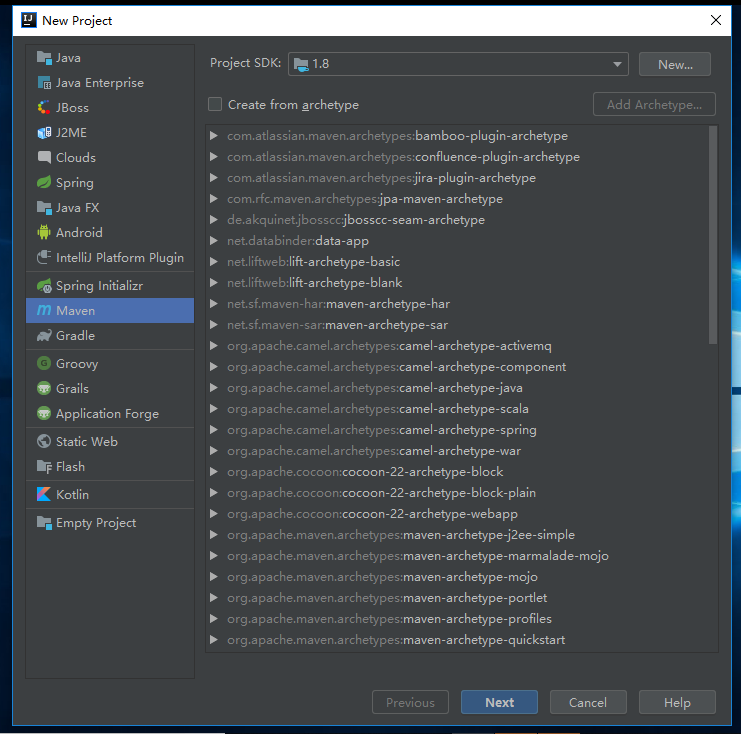
然后是组id和工件id,自己命名,然后next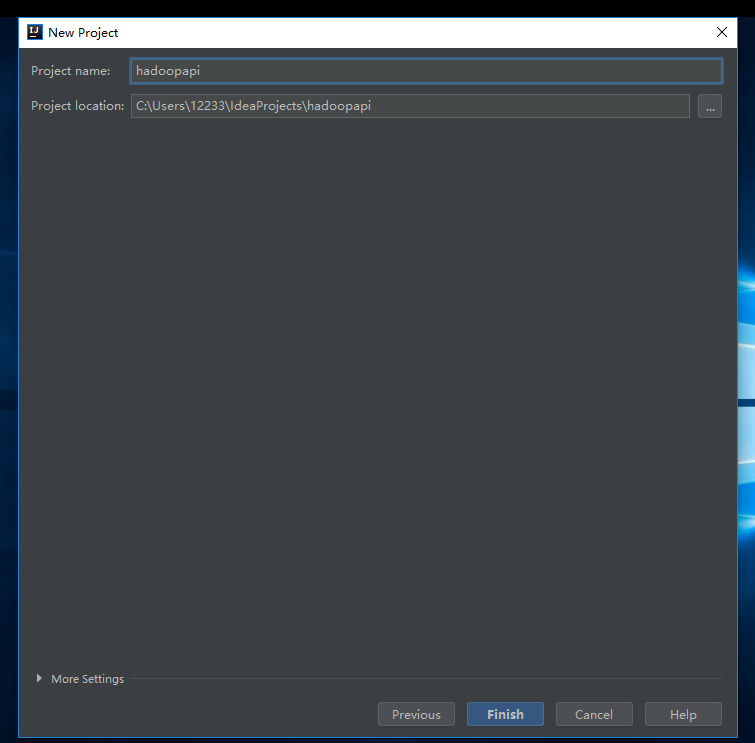
然后是项目名称和项目存放地址,然后finish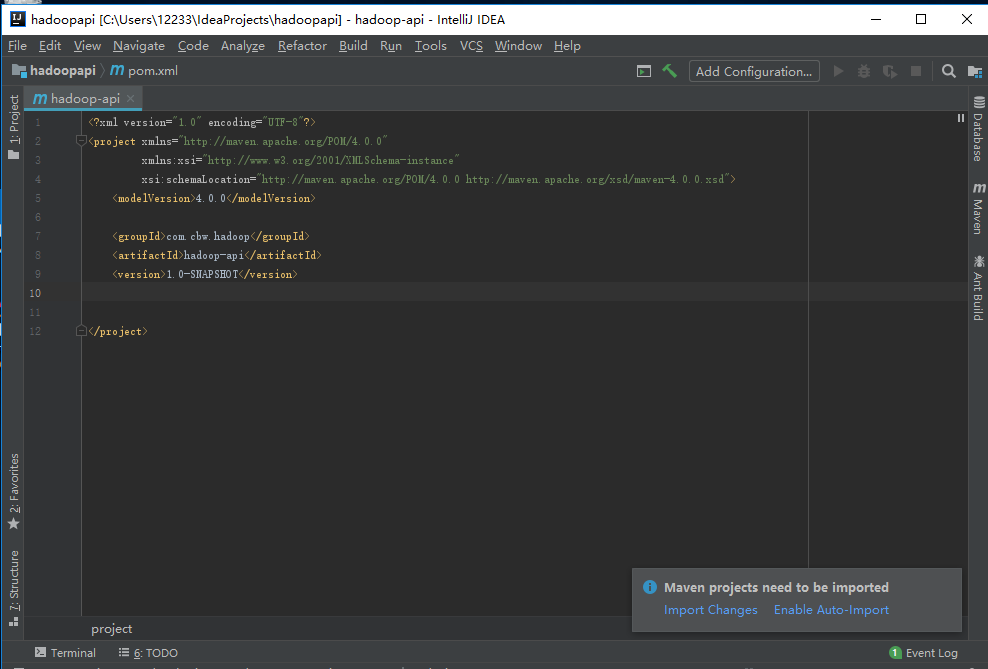
进来项目主页,右下角会有提示,我们选择右边的Enable Auto-Import,这个是自动给我们导入包
我们先设置一下maven环境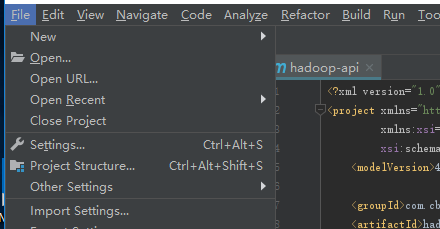
file->settings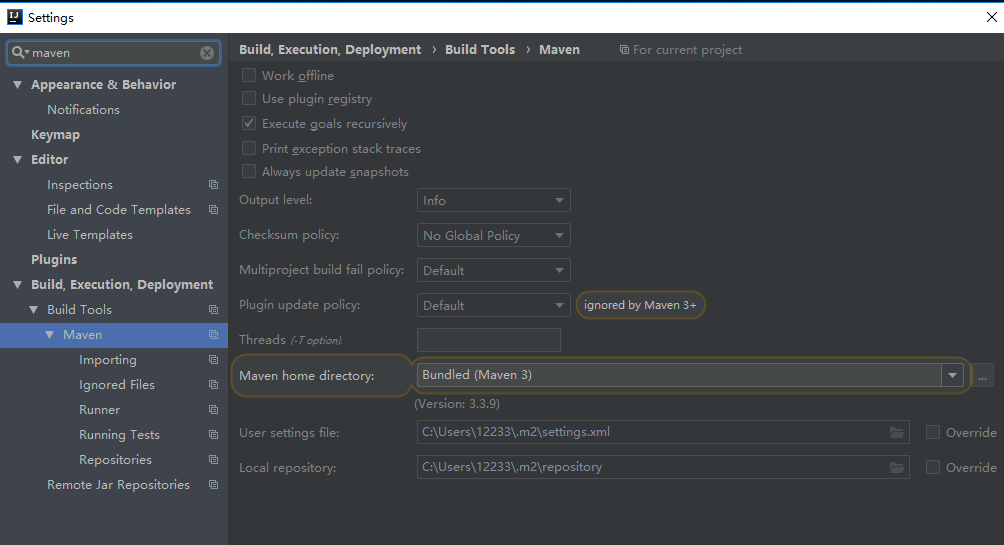
输入maven到这个页面,我们要修改的是下面两个
第一个设置为maven安装的根目录
下面一个设置为maven->conf->settings
然后在pom.xml文件里面添加一些代码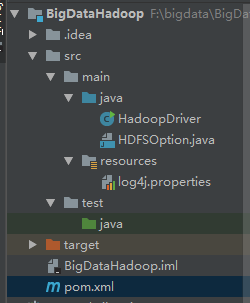
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency>
</dependencies>
log4j是日志打印文件,可以将mapreduce的运行日志打印在控制台,hadoop-client是hadoop客户端,然后我们在src的java文件夹新建一个类,写入wordcount代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class HadoopDriver {
public static class HadoopMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text textKey = new Text();
private IntWritable count = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(",");
for (String word : words) {
textKey.set(word);
count.set(1);
context.write(textKey, count);
}
}
}
public static class HadoopReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//相同的key聚合 几种类型的key调用reduce几次
private IntWritable count = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
count.set(sum);
context.write(key, count);
}
}
public static void main(String[] args) throws Exception {
Configuration config = new Configuration();
//把任务封装到job对象
Job job = Job.getInstance(config);
//
job.setJarByClass(HadoopDriver.class);
job.setMapperClass(HadoopMapper.class);
job.setReducerClass(HadoopReducer.class);
//指定map
// 如果map的输出和reduce输出key-value类型一致 可以不写map
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定reducer
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//告诉hadoop集群 以什么方式读取数据 从哪里读取
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, new Path("D:\\word.txt"));
//告诉hadoop集群以什么样的方式写入数据 数据写入到哪里
job.setOutputFormatClass(TextOutputFormat.class);
Path path = new Path("D:\\wordcount");
FileSystem fs = FileSystem.get(config);
if (fs.exists(path)) {
fs.delete(path, true);
}
TextOutputFormat.setOutputPath(job, path);
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这些包,maven会帮你自动下载,你只需要导入就行,计算机必须联网
我们来测试一下,在D盘创建word.txt文件,里面用,作为分隔符写字母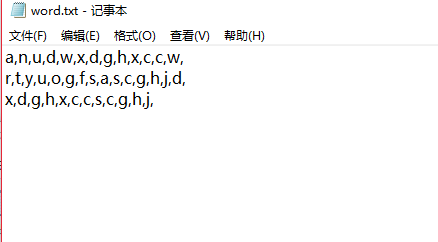
然后我们运行wordcount程序
运行结果如下,运行日志被打印出来了,可以看到运行成功,没有报错,我们来检查下统计结果,打开D盘,找到wordcount文件夹
里面有4个文件,我们打开最后一个
可以看到字母统计完成

