大数据学习
– 小实验
环境:
idea:ultimate 2018.1
系统:windows10 家庭版
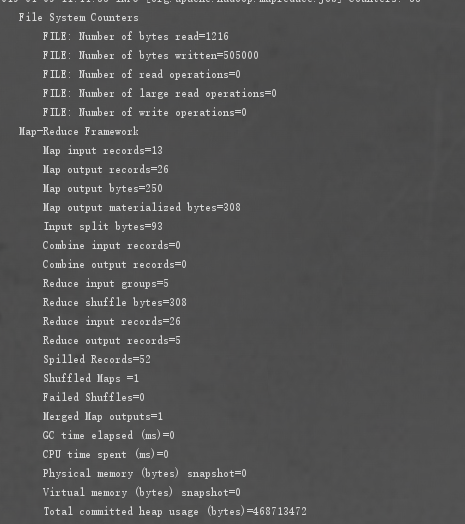
1.Count计数器
2.自定义计数器
(1)枚举类型
在mapper中定义CustomCount枚举类型
enum CustomCount{
MAP_RUN_COUNT;
}
然后在map方法中写context.getCounter(CustomCount.MAP_RUN_COUNT).increment(1l);
后面的increment是增加count值的,参数是1l,参数类型是long
计数结果
(2)键值对类型
在reducer中定义context.getCounter("REDUCE_RUN_COUNTS","running_counts").increment(1l);
使用键值对形式定义计数器
3.局部合并
combiner和reducer的区别在于运行的位置:
- Combiner是在每一个maptask所在的节点运行
- Reducer是接受全局所有Mapper的输出结果
- Combiner的意义就是对每一个maptask的输出进行局部汇总,以减少网络传输量
具体步骤:
自定义一个Combiner类继承Reducer类,重写reduce方法
在job中设置:job.setCombinerClass(CustomCombiner.class);
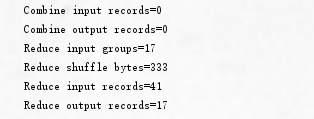
这是没有设置Combiner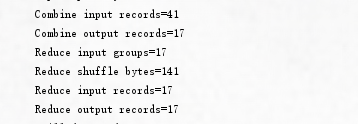
这是设置了Combiner
可以明显的看到reduce的输入次数和shuffle过程的字节数有所减少
注意:求平均值得业务不适用局部聚合,这样会使结果不准确

